

原是体系结构的“课程研究报告”。不过既然已经花了那么多时间搜集资料,写出来的东西只当成作业上交未免有点浪费。
虽然RISC-V的向量扩展(V-extension)目前还在草案阶段,但是已经基本成型了。出于对RISC-V的兴趣,我决定以其向量扩展为研究学习主题。
我原先以为RISC-V向量扩展的的设计会类似Intel的SSE、AVX指令集,但是查找资料的结果告诉我并非如此。与SIMD指令的路子不同,RISC-V选择了向量处理,类似上课讲过CRAY向量机的处理方式。RISC-V文档中,压缩整型扩展(P扩展)被砍掉了,另外提出了向量扩展(V扩展)。关于这点,Patterson(RISC-V的发起人之一,《计算机体系结构:量化方法》的作者之一,图灵奖得主)甚至还专门写了一篇很有意思的文章,批评SIMD指令并不是一个好设计。
SIMD是Flynn分类法中”单指令多数据“的简写,为何这一数据级并行的基本思路会受到Patterson的批判?下面我简要概括一下Patterson等人的理由。
SIMD指令为什么「被认为是有害的」?
在发表于SIGARCH上的《SIMD Instructions Considered Harmful》一文中,Patterson和Waterman提出了以下理由,说明为什么SIMD指令的出发点看似仅仅是划分寄存器,允许同时对不同部分进行运算,但是却”好心办了坏事“,带来不少害处。
对于元素宽度不同的划分方式,SIMD指令集需要提供不同的指令,硬件也有些复杂
当SIMD寄存器改进得更宽(宽一倍),为了兼容性,指令数量也几乎需要翻倍
SIMD指令带来的复杂程度,与带来的性能提升或许并不匹配
SIMD指令本质上缺乏灵活性,因此随着指令架构的演进不可避免地变得非常庞大、复杂。比如,Intel的IA-32从1978年至今从80条指令演化到了1400条指令,这么大数量的增加很大程度上是为了SIMD指令。对比Intel的指令集文档和RISC-V的文档页数,前者不仅分成好几卷,一卷基本上就有几千页,后者总共核心内容只有几十页,总共加在一起应该也没有500页。SIMD指令很大程度上使得指令级非常复杂,并且复杂程度很可能随着架构演进,还要继续增加。
关于第三点,两位作者对一个平凡而简单的程序进行了分析,统计指令的数量,假设n=1000
void daxpy(size_t n, double a, const double x[], double y[])
{
for (size_t i = 0; i < n; i++) {
y[i] = a*x[i] + y[i];
}
}
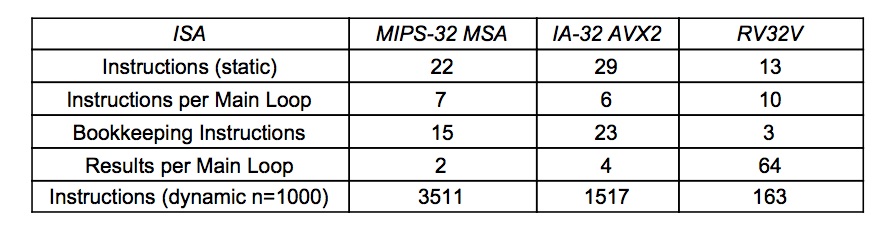
使用CRAY式向量流水线的RV32V在n=1000时几乎是完胜使用SIMD的前两者。据此测试结果,两位作者不得不对SIMD指令这种方式带来的提升提出质疑,并认为SIMD指令不是一个好思路。
当然对SIMD指令的批判并不意味着SIMD一无是处,在图像处理中,彩色像素几乎总是包含三个值(RGB),经常需要对这三个值做相同的操作,这种情况下SIMD就是非常好的方案。按照我个人的理解,两位作者意指传统的SIMD指令带来的代价太大,而不是SIMD这一思路本身无用。
RISC-V的向量扩展和粗暴地添加指令和硬件不同。Eirk Engheim的文章对这种动机进行了进一步说明:“用向量架构,可以更优雅地实现数据级并行。”
RISC-V的向量指令扩展
我尝试阅读了RISC-V向量指令扩展的细则(spec),虽说不能完全掌握其使用,但是对其灵活性有更直接的感受。
基本概念
向量扩展指令集添加了若干个CSR(控制状态寄存器),定义了一些基本的控制状态,比如向量开始位置、向量数据类型、向量长度等等。其中我觉得最重要的是vtype寄存器,灵活性就体现于此,后面具体说明。
还有32个向量寄存器v0-v31,每个寄存器都有VLEN个位。
向量指令扩展如何处理向量
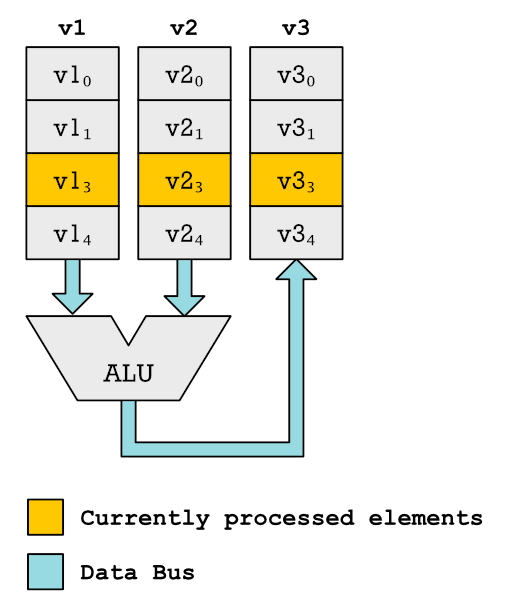
如图(图来自Erik Engheim的文章),不同于SIMD,一次只使用一个ALU,只对一对元素进行操作,但是向量寄存器可以很长。
具体实现中在vtype寄存器中的[5:3]位表示vsew[2:0],[2:0]位表示vlmul[2:0]。前者设置SEW(选中元素宽度),后者设置LMUL(分组因子)。
SEW表示了一个向量寄存器中有多少个元素,如果SEW是16,那么向量的每个元素就有16个位,向量包含的元素个数就是VLEN/16。
LMUL表示分组方案,上面提到向量寄存器可以很长,但是实际上「很多向量」和「很长的向量」不能同时取得,分组就是一种折衷方案(compromise),当LMUL是1的时候,不分组;当LMUL是2的时候,两个向量一组,比如,v0和v1被接在一起了,v2和v3接在一起,向量长度相比不分组就长了一倍。LMUL取4、8以此类推。LMUL还可以取分数,缩短向量长度。具体的分组方法和接法在spec中有图表说明。
我觉得SEW和LMUL的设置就是RISC-V向量扩展灵活性的核心。通过在CSRvtype中设置这两个参数,就能调整机器看待向量的方式,可长可短,可宽可窄,按需设置。另外CSR必须用专门的指令进行修改,spec中说明这可以简化CSR的管理。
具体的向量指令
使用vsetvl系列指令设置vtype寄存器。spec中建议汇编器使用一些预先定义的名字来表示LMUL。比如
vsetvli t0, a0, e8, m2 # SEW= 8, LMUL=2
从内存中加载向量使用vl系列指令,写回内存中使用vs系列指令。加载和写回都有三种寻址方式,如同课上说过的,unit-stride(单位步长)、stride(常数步长)、indexed(索引)。第一种指定位置开始,一次取一个元素。第二种从指定位置开始,先取一个元素,然后走一个给定的步长后再取下一个元素(适合行主序存储时取列),索引则需要提供另一个向量提供各个元素的偏移量(适合稀疏的数据)。
spec举例如下。vd代表目标向量寄存器。(rs1)代表主存中的地址,用一个通用寄存器给出,vm是掩码,此处不讨论。
vle8.v vd, (rs1), vm # 8-bit unit-stride load
vlse8.v vd, (rs1), vm # 8-bit strided load
vle32.v vd, (rs1), vm # 32-bit unit-stride load
vlse32.v vd, (rs1), vm # 32-bit strided load
vluxei8.v vd, (rs1), vs2, vm # unorderd 8-bit indexed load of SEW data
vluxei32.v vd, (rs1), vs2, vm # unorderd 32-bit indexed load of SEW data
写回内存只需将指令换成对应的vs系列指令。
向量运算部分,十分简单,不过浮点指令和整型指令是分开的,另外还有一族加宽度的指令,即结果的SEW是操作数SEW的两倍。
以整型加法为例,不仅有向量加向量,还有向量加标量,向量加立即数。减法、乘法、移位都类似。甚至还有取最值(最大值、最小值)的指令。
vadd.vv vd, vs2, vs1, vm # vector add vector
vadd.vx vd, vs2, rs1, vm # vector add scalar
vadd.vi vd, vs2, imm, vm # vector add immediate
上面提到的掩码可以用于合并向量。掩码实际上也存储在一个向量寄存器中,掩码向量之间可以做逻辑运算。被“掩”住的元素不会发生异常。
简单程序
上面daxpy函数,Patterson的文章给出了RISC-V指令集和IA-32
AVX的汇编代码
# a0 is n, a1 is pointer to x[0], a2 is pointer to y[0], fa0 is a
0: li t0, 2<<25
4: vsetdcfg t0 # enable 2 64b Fl.Pt. registers
loop:
8: setvl t0, a0 # vl = t0 = min(mvl, n)
c: vld v0, a1 # load vector x
10: slli t1, t0, 3 # t1 = vl * 8 (in bytes)
14: vld v1, a2 # load vector y
18: add a1, a1, t1 # increment pointer to x by vl*8
1c: vfmadd v1, v0, fa0, v1 # v1 += v0 * fa0 (y = a * x + y)
20: sub a0, a0, t0 # n -= vl (t0)
24: vst v1, a2 # store Y
28: add a2, a2, t1 # increment pointer to y by vl*8
2c: bnez a0, loop # repeat if n != 0
30: ret # return
# eax is i, n is esi, a is xmm1,
# pointer to x[0] is ebx, pointer to y[0] is ecx
0: push esi
1: push ebx
2: mov esi,[esp+0xc] # esi = n
6: mov ebx,[esp+0x18] # ebx = x
a: vmovsd xmm1,[esp+0x10] # xmm1 = a
10: mov ecx,[esp+0x1c] # ecx = y
14: vmovddup xmm2,xmm1 # xmm2 = {a,a}
18: mov eax,esi
1a: and eax,0xfffffffc # eax = floor(n/4)*4
1d: vinsertf128 ymm2,ymm2,xmm2,0x1 # ymm2 = {a,a,a,a}
23: je 3e # if n < 4 goto Fringe
25: xor edx,edx # edx = 0
Main Loop:
27: vmovapd ymm0,[ebx+edx*8] # load 4 elements of x
2c: vfmadd213pd ymm0,ymm2,[ecx+edx*8] # 4 mul adds
32: vmovapd [ecx+edx*8],ymm0 # store into 4 elements of y
37: add edx,0x4
3a: cmp edx,eax # compare to n
3c: jb 27 # repeat loop if < n
Fringe:
3e: cmp esi,eax # any fringe elements?
40: jbe 59 # if (n mod 4) == 0 go to Done
Fringe Loop:
42: vmovsd xmm0,[ebx+eax*8] # load element of x
47: vfmadd213sd xmm0,xmm1,[ecx+eax*8] # 1 mul add
4d: vmovsd [ecx+eax*8],xmm0 # store into element of y
52: add eax,0x1 # increment Fringe count
55: cmp esi,eax # compare Loop and Fringe counts
57: jne 42 <daxpy+0x42> # repeat FringeLoop if != 0
Done:
59: pop ebx # function epilogue
5a: pop esi
5b: ret
后者在真正开始计算前需要做很多准备工作,但是循环体中的指令少;前者整体更简洁,但是循环体中的指令多。但是依靠向量指令和流水线,后者可以规避这一点。看完程序之后我不得不同意RISC-V确实更加优雅。
总结
我没有预料到对RISC-V指令的学习会引出这么多有趣的内容,看似人畜无害的SIMD居然会引发这么多争论。
看完资料后我在想,是否真的是向量指令永远优于SIMD指令?我觉得如果向量长度很短,向量处理指令未必能够更快,SIMD指令也许更好。因此,对SIMD指令和向量指令的优劣对比都是综合比较的结果,并不是一方全方面完胜另一方。至于谁的trade-off更优,也许只有实际应用才能告诉我们答案。
参考文献
Patterson和Waterman的文章 https://www.sigarch.org/simd-instructions-considered-harmful/https://www.sigarch.org/simd-instructions-considered-harmful/
Eirk Engheim的文章 https://medium.com/swlh/risc-v-vector-instructions-vs-arm-and-x86-simd-8c9b17963a31
RISC-V V-extension SPEC https://github.com/riscv/riscv-v-spec